





The main objective of Tulipp is to provide at the end of the project a reference platform through associated guidelines so that image processing board manufacturers could develop a low-power high performance computing system with the expected performances. The project will concentrate on interfaces between the components of the platform as well as design and implementation rules. Following the rules, anyone will be able to produce a compliant platform and benefit from the technological advances generated by the project. The interfaces will be defined, so as to enable any industrial to produce any sub-part of the platform and plug it to other existing platform so as to create a new Tulipp platform instance.
The Tulipp reference platform will consist in three layers:
- The hardware architecture;
- The real time operating system (RTOS) and libraries;
- The tool chain.
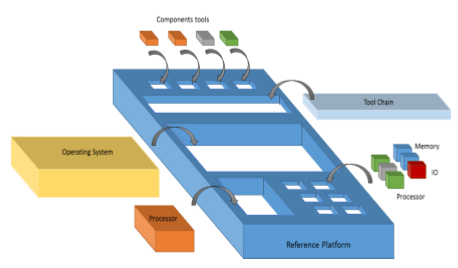
The hardware architecture will be a template of the heterogeneous computing system. Such a trend can currently be noticed from chip manufacturer, producing heterogeneous systems for embedded application. For instance, NVIDIA with the TegraK1™ which delivers high performance with both a cluster of ARM processors and a General Purpose Graphic Processor Unit (GP-GPU), or Xilinx with the Zynq™ or the UltraScale™ MPSoC Architecture. While one of such chips will be efficient at processing a part of an application, another might be better for another part of the same application. Tulipp will look for a chip that would embed as many different type of processing element as image processing is using. As such a chip does not exist and might never exist as such, its hardware platform template will allow anyone to combine a variable number of chip and different type of chips on a single board. But having such a heterogeneous system brings its drawback: when an application only needs one chip at a given time, then the unused chips will still consume power. Tulipp platform will enable chips or communications to be switched Off when unused. Thus, for each part of an application, the best suitable chip will be selected while the other chips will be switched Off. If more computation is required by the application, then more chips can be activated.
The project will define how to select chips suitable to build a Tulipp platform instance, how to interconnect such chips and how to manage the selection and switch Off mechanism at run-time. Thus it will enable to reduce the power consumption of the whole system. The efficiency of the Tulipp platform will greatly benefit from the improvement of available chip technology and go one step further by using the best one for each part of a given application.
Doing so, the board will be fine-tuned or configured for each application. The chip frequencies will be adjustable when possible on the given chip; when implementing the application on FPGA, the frequency will be adjusted to the lowest value that fits the application needs.
The real time operating system and low level libraries designed for low-power and image processing will have to match the application requirements (latency, memory size and consumption). It will run on the instantiated processors of the hardware layer, which means communication and synchronisation mechanisms have to be implemented between the processors. The footprint – binary size – of the RTOS must be small (a few tens of kilobytes) because each hardware component embeds only a small local memory. Bigger memories like DDR, will also be available but the access time will not be compatible with running application at real-time. Some of the targeted components that will be implemented on the elementary board will come with some primitives to be integrated or wrapped in the library available to programmer. Standard APIs will be extended or shorten to cope with low-power and image processing. Extensions or modified standards will be proposed as pre-norm.
The solution proposed is a brand new kernel design, specifically designed for multicores and under constraints such as the small footprint. This is a combination of several features. One will be to use a master-slave micro-kernel design specifically built for better scalability. The micro-kernel is separated into small parts, and only those that need to run on a core are invoked when needed. This reduces locks and allows for a small footprint. Second, we will be using power-aware schedulers (Earliest Deadline First (EDF) based instead of Rate Monotonic (RM) based). The power aware scheduler balances the requirements of the task, e.g. when it needs to complete, with the power that it will use by running on a given frequency on a given processor. This creates thus an optimal schedule using the lowest power. Also the EDF based scheduler is able to reach a high utilization rate even for parallel architectures, thus also decreasing the overall power usage. Efficient and scalable mechanisms will be used for resource sharing and for IPC. These solutions can be implemented into a small kernel that fits into a small low power platform. The main advantage of the solution is its efficiency for parallelism and power optimization.
The tool chain will have to capture the application and help to map it on the heterogeneous platform. As each hardware component comes with its own development tools, and as such tools are dedicated to the specific hardware component they are meant for (e.g. NVIDIA components come with its CUDA development studio, Xilinx components come with the Vivado development studio…), the Tulipp tool chain will have to enable each component tool to be smoothly integrated next to the others and will facilitate the access to the component development studios. The Tulipp tool chain will thus help the designer in mapping each part of the application on the best suitable component for power efficiency and generating the necessary code for the RTOS to drive the hardware (i.e. switch off the unnecessary components, preload the components with its application binary before they are used, etc…). In the project, as a first step towards a sophisticated tool chain, the user could be asked to map the application thanks to pragmas.
Several processing technologies are available today for high performance embedded applications. General purpose processors, multi/manycores, DSPs, GPUs and FPGAs target different areas of applications, partially overlapped, ranging from controlbased to progressively more data-flow oriented static algorithms. Areas are however overlapping, an application may often reasonably be run by several types of architecture, but with different achievements in terms of throughput, power consumption, programming cost, etc… Even the DSP oriented multi/manycore architectures, be it using the same silicon technology with similar power budgets, have their domains of better efficiency at different areas in the applications spectrum. Aggressive manycores like GPUs target high throughput by using a large number of cores, but they actually reach their best performance only when the execution is highly repetitive and has be running for a long enough time to give the heavy processing cores structure a chance to reach a stable cruising state. Massive parallelism may happen to lack reactivity for some agile real-time applications, by e.g. missing deadlines or achieving a poor ops/watt ratio compared to processors with less parallelism or FPGAs. Considering power consumption as a major performance criteria, different applications or different parts of a same application, can be preferably allocated to different styles of computing architecture. Heterogeneous architectures give that opportunity. Current technology permits to install on a board a very comfortable amount of potential computing power. The achieved throughput on applications is nearly always limited by I/O bandwidths or other factors than the number of operators on-chip. Based on that, an application can be deployed, as far as its throughput and latency demands are respected, over the computing places that run it together at the best energy cost. This necessitates some resource management facilities on the board so as to limit at best the energy spent in unused resources.
The Tulipp tool chain will primarily reduce the platform adaptation time which is a one-time cost incurred each time a new platform is used. The reason is that we will use existing component tools for application development. However, the extensive profiling support, visualisation capabilities, interface functionality and the optimized image processing functions available in the tool chain will contribute to reducing application development time as well.
Thus, the KPIs for the Tulipp tool chain are:
Platform adaptation time shall be reduced by at least 80% when the final tool chain is used compared to a manual implementation;
Application development time shall be reduced by at least 10% when the final tool chain is used compared to a manual implementation;
The tool-assisted optimisation shall achieve at least 80% of the energy efficiency of an expert designer performing a manual implementation.